(OLD)생각이 없는 프로그래밍: 5번을 새로 짠 머신 러닝 데이터 관리 시스템
주의) (OLD)로 표기된 글은 현재 제 생각과 크게 다르거나 중대한 오류가 있지만
아카이브용으로 유지하는 글입니다
나는 식질머신을 위한 데이터 관리 프로그램을 만드는데 5번 실패했다.
시행 착오라고 포장할 순 없다... 나는 실패할 생각으로 5번 실패한 게 아니다. 절대로 버릴 생각으로 짜지 않았다...
언제나 최선을 다했지만 매번 실패한 것이다.
지금은 6번째 츄라이를 하고 있다.
그래서 계속해서 왜 그렇게 실패했는지, 왜 간단하다고 생각한 일이 그토록 어려운지
계속해서 곱씹고 있다.
또 다시 실패할 수는 없다... 시행 착오는 있어도 실패는 할 생각 없다.
나는 왜 실패했는가?
가장 주된 이유는 충분히 생각 하지 않았기 때문이다.
(아니다, 학습을 안 해서다. 이는 과거OLD의 생각이다)
식질머신(머신러닝)을 위한 데이터 관리 프로그램은 사실 정말 별 거 없어 보인다.
머신 러닝 데이터 관리 프로그램이 해야하는 일은
- 여러 원천에서 데이터를 긁어모으고
- 그것들을 학습 가능한 형태로 바꾼다.
이게 끝이다. 정말로 간단해 보인다...
그러나 이 프로그램은 내 상상보다 더 복잡했다.
머신 러닝용 데이터를 관리하는 것은 내가 생각했던 것보다 훨씬 더 크고 복잡하고 어려운 일이었다.
결론부터 말하자면, 나는 5번이나 당하고 나서야 좀 더 크게, 더 확실히, 더 많이 생각해야한다는 것을 깨달았다.
나는 너무 생각을 작게, 얕게, 덜 했다.
5번 갈아 엎기의 역사
1번마: szmc_data_old 165커밋
- 165 커밋, 2019/3/25 ~ 2019/5/13
- 관련 블로그 글: szmc_data: 다섯번을 바닥부터 다시 짠 프로젝트
가장 처음, 첫번째 시도에서 나는 폴더 하나에 다양한 기능의 스크립트가 들어있는 구조로 코드를 짰다.
나름 스크립트마다 CLI 인터페이스가 있었다.
그러나 이들은 한번 사용되고 다시는 사용되는 일이 없었다.
재사용성 따위는 없었다.
이 때를 생각하면... 코드들이 정말로 스크립트였기에,
다양한 데이터 소스의 데이터를 모으는 게 거의 불가능했다.
그걸 하려면 데이터 합병을 위한 스크립트를 새로 짜야 했다.
또한 하나의 폴더에 소스가 계속 쌓여갔기에, 어떤 일을 하려면 무슨 코드를 돌려야할지 알 수가 없었다.
직감적으로 코드를 나눠야한다는 생각을 하기 시작했다.
그래도 이 첫번째 프로그램은 나름 성공적이었다.
첫번째 프로그램으로 논문도 쓰고 졸작 상도 받고...
그러나 프로그램 그 자체는 확장성도 없고 재사용성도 없는, 스크립트 이상도 이하도 아니었다.
2번마: data_lake
레포: 60 커밋, 2019/11/20 ~ 2020/1/20
두번째 시도에서는 Clojure를 적용했다. 그러나 문제는 언어가 아니었다.
프로그래머가 제대로 생각하지 않으면 어떤 툴을 써도 개같은 코드가 나온다.
두번째 시도에서 가장 기억에 남는 실패는 어느 순간부터 새로운 명령어와 기능을 넣는게 너무 힘들어졌다는 점이었다.
clojure에서 CLI를 위한 라이브러리를 제대로 조사하지 않고 입력되는 arg를 직접 파싱하여 만들어 짰다.
그건 재앙이었다.
나는 사용자로서 프로그램을 쓰는 방법을 매번 까먹었고,
개발자로서는 어떻게 새 기능을 넣어야할지, 어디에 새 기능을 둬야할지 알 수가 없었다.
그 외에도 늘 쓰던 파이썬이 아니라서 여러모로 개발이 느려졌다.
에디터 기능은 적응하기 어려웠고, 새로운 라이브러리를 설치하는 방법도 배워야 했었다.
특히 설치하고는 한번도 쓰지 않은 자바 이미지 해시 라이브러리를 lein으로 설치하는 게 힘들었던 기억도 난다...
이걸 왜 설치했던걸까...
아무튼 2번째 시도도 완벽하게 처망했다. 빨리 만들어야 되는데 익숙하지 않은 환경을 쓴 것도 문제였지만,
더 핵심적인 이유는 충분한 조사를 하지 않았다는 것과, 이번에도 충분히 생각하지 않았다는 점이다.
두번째 프로그램의 가장 끔찍한 점은
이걸로 수행한 실험이 단 하나도 없다는 점이다.
전형적인 Hype Driven Development이다.
완벽한 시간낭비였다.
3번마: old-data-warehouse
레포: 119 커밋, 2020/4/19 ~ 2020/6/25
세번째 시도에서는 파이썬으로 돌아왔다.
그리고 python-fire라는 걸출한 CLI 라이브러리를 적용해 개발과 사용 자체는 훨씬 편해졌다.
그러나 여전히 깊이 생각하지 않고 CLI의 인터페이스를 짰다.
결국 비슷한 일을 하는 CLI 명령이 여럿 있었고, 점점 새 기능을 어디에 넣어야할지 알 수 없게 되었다.
결과적으로 어떤 일이 일어났을까?
여러 데이터 소스(Manga109, Danbooru2018, Contributed)마다 동일한 일을 하는 함수가 생겼다.
데이터 소스마다 담당하는 모듈을 짰었다.
모듈 이름이 다르고, 그 안의 함수로 이름은 같고 비슷한 일을 하는 코드들이 중복되어 작성되었다.
코드 재사용? 그딴 건 없었다. 비슷한 일을 하는 코드를 리팩토링 하는 건 거의 불가능했다.
또 이때도 DB를 썼는데... 이 또한 깊게 생각하지 않고 스키마를 짰다.
결과적으로 디비를 썼는데도 데이터는 통합되지 않았고, 코드는 따로 놀며 중복되었다.
세번째 시도에서는 tfrecord로 데이터를 생성하고 그걸 tf2로 짠 모델로 학습해 보았다.
그러나 이전에 썼던 논문에서 더 나아진 점은 없었다...
4번마: old-2-data-warehouse
레포: 104 커밋, 2020/7/22 ~ 2020/8/18
4번째부터 Hammock Driven Development(HDD, 해먹주도개발)를 하려고 했지만, 실패했다. 나는 맞다고 생각하고 했지만, 완전 잘못 하고 있었다.
지금 생각해보면... 이 때는 해먹 주도 개발을 어떻게 하는 것인지 제대로 알지 못했다.
나는 해먹 주도 개발을 하는 줄 알았지만 사실 폭포수 프로세스로 개발을 하고 있었다.
생각을 하고 설계를 하긴 했지만...
올바르지 못한 도구(google docs)로 문서를 작성했고, 유지 보수가 불가능했다.
또한 정말로 해결해야 하는 문제에 대해서 생각하지 않았다.
데이터 관리 시스템이라는 "모듈" 하나에만 집중을 했고, 실제로 어떻게 사용될지 생각하지 않았다.
관련 블로그 글: 머신러닝 메타데이터 관리에서 RDB가 필요한가?
이 프로그램을 포기하게 만든 가장 큰 실수는
문제에 대한 해답을 비판적으로 판단하지 않은 점.
그리고 사용을 염두에 두지 않은 DB 스키마 작성이었다.
이번 시도에서, 나는 시스템에 존재하는 모든 데이터를 UUID로 표현하여, 데이터의 관계를 DB로 표현하려 했다.
즉 만화 이미지도, 이미지에 맵핑되는 마스크도, 이미지의 어떤 속성을 의미하는 레이블도 다 UUID를 붙이려 했다.
언뜻 보면 말이 되는 것 같았다. 실제로 ERD도 대강 그려보기도 했다.
그러나 실제 사용이 거의 불가능했다.
이미지나 마스크를 열려면 SQL을 써야 했다. 이건 정말 끔찍했다.
게다가 snet을 위한 이미지 - 마스크 데이터셋을 만들기 위한 SQL이 정말정말 어려웠다.
내가 SQL 실력이 없기도 했지만, 아무리 생각해도 이게 대체 무슨 짓인가 했다.
왜냐면 3번째 시도까지는 그냥 하면 되는 일들이, DB를 넣으니까 너무 어려워서 도저히 손을 댈 수 없는 정도였기 때문이다.
결국 개발이 느려지다 못해 멈춰버리고, 나는 4번째 프로그램을 포기하게 된다.
결과적으로 4번째 프로그램으로는 수행한 실험이 하나도 없다.
시도한 기술들
4번째 프로그램에는 여러가지를 도입해 보았다.
파이썬 함수에 타입을 달면서 mypy도 써보고
ORM도 써봤다. TDD를 위시한 테스트도 꼬박꼬박 달았다. (이전까지는 스크립트 느낌이라 테스트가 없었다)
어떤 모듈에는 PBT까지 달기도 했다.
근데 파이썬 타입은 잘 작동하지도 않았고, ORM은 무슨 똥덩어리가 잔뜩 붙은 돼지색기 마냥 느려 터져서 사람만 빡치게 했다.
TDD라면서 붙여 놓은 테스트는 아무 의미도 없었고, PBT는 테스트가 느려지기만 해서 도중에 갖다 버렸다.
스키마에서 SQL을 실행해 데이터를 가져와 봤다면, 내가 무슨 짓을 하고 있는지 만들기 전에 알 수 있었을 것이다.
ORM이 어떤 놈인지 만들어 보기 전에 실험해볼 수 있었을텐데. 계속해서 그런 생각이 들었다.
4번마 낙마의 근본 원인
여기까지가 구체적인 이야기이고, 더 근본적인 실패 원인을 이야기해 보자.
4번째 실패의 진정한 원인은 내가 제대로된 설계를 하지 못했기 때문이다.
아까도 이야기했지만 나는 해먹 주도 개발이 아니라 혼자서 폭포수 프로세스로 개발을 하고 있었다.
이때의 나는... 다음과 같은 일을 "설계"라면서 하고 있었다.
- 문제보다 해답에 집중하여, 심하게 세세한 부분까지 계획을 세운다.
- 설계 문서를 한번 작성하고 변경하지 않는다 - 다시 돌아오지 않는다.
- 자신이 모르는 것을 찾아보지 않고, 자기 세계에 갇혀 있는다
- 문제에 대한 해답을 단 하나만 생각한다.
- 자신이 생각해낸 해답이 옳다고 생각하고, 비판적으로 사고하지 않는다.
- (개인 프로젝트) 작은 모듈에 매몰되어 전체를 생각하지 않는다.
이게 바로 폭포수 프로세스 / 오버 띵킹이다
해먹 주도 개발을 할 때 폭포수 모델을 하는게 아닌지 정말로 조심해야 한다.
너무 작게 생각했고, 피드백을 받고 설계를 고치며 생각을 수정하지 않았고, 해답을 비교하지 않았다.
다른 사람들이 어쩌는지 확인하지 않았고, 사용자(미래의 나)와 협업자(미래의 나)를 고려하지 않았다.
설계 관련 깨달음
4번째 프로그램을 만들 때, HDD에서 이야기하는 Analysis & Design이 뭔지 알지 못했다.
산출해야 하는 설계가 어떤 것인지 몰랐다.
지금은 A&D와 설계가 뭔지 대강 알고 있다:
- Analysis & Design은 문제를 이해하고 제안하는 해답이 문제를 해결하는지 확인하는 작업이다.
- 설계는 어떤 것을 다시 결합할 수 있게 쪼개는 작업이다.
이런 개념적인 것 외에도, 실전적으로,
해먹 주도 개발을 하려면 일단 문서화를 위한 적절한 도구와 다이어그램을 그릴 도구가 필요하다. (OLD 주의: 아니다..)
특히 유지보수가 가능하고, 단계적인 문서를 형성할 수 있는 문서화 도구는 정말로 필수적이다.
개인적으로는 문서화 도구로 노션을 추천하며, 나는 그림은 아직 그냥 종이 / 서피스로 그리고 있다. 아직은 나만 보면 되서...
잘못된 설계의 "냄새"
그리고... 4번째까지 해보면서 잘못된 설계의 냄새를 하나 알게 된 거 같다.
새로 추가하는 기능을 어느 모듈에 넣어야할지 모르겠다면, 설계가 잘못된 것이다.
최소한 생각해 본 적이 없는 것이니, 설계를 변경해야할 수도 있다.
돌이켜보면 세번째 시도부터는 모듈화를 하려고 했지만 항상 실패했다. 네번째나 다섯번째도 비슷했다.
프로그램을 짜다 보면 항상 이런 식이었다.
- 뭐지? 이건... 생각 못했는데.... -> 임기응변으로 때운다
- 당장 XX를 해야 하는데 이걸 어느 모듈에 넣어야 하지? -> 임기 응변으로 때운다
항상 생각하지 못한 일이 일어났다.
특히 실제로 하는 일은 정말 뻔한 건데, 내가 쪼개 놓은 모듈 중 대체 어디에 넣어야할지 몰랐다.
왜 그렇게 되었을까? 그저 거기까지 생각하지 못했기 때문이다.
약간 삼천포로 빠진 거 같다. 5번째 프로그램 이야기를 하자.
5번마: data-warehouse
레포: 150 커밋, 2020/8/20 ~ 2020/12/3
4번째에서 압도적으로 폭망하고... 나는 왜그렇게까지 망했나 생각을 해 보았다.
이 때는 4번째 실패의 원인은 DB가 아닐까..... 하는 생각을 했다.
아무래도 그래 보였다. (사실은 아니었지만)
그래서 고대로 돌아갔다. DB가 없던 그 시절로. 아! 옛날이여...
데이터 소스마다 json 혹은 yaml로 메타데이터를 만들어 데이터의 관계를 표현했다.
그리고 이미지와 마스크는 부모 디렉토리만 다르고, 같은 이름으로 저장하여 관계를 암시적으로 표현하였다.
그리고 아무 쓸모 없는 테스트는 때려 치우고, 스크립트마냥 직접 눈으로 보고 확인하는 수동 테스트를 수행하였다.
생각보다는 괜찮았다! 5번째 프로그램으로 꽤 많은 작업을 하였다.
Manga109 데이터, Contributed 데이터를 어노테이션하고 병합하여 데이터셋을 만들고
이를 이용하여 텍스트 유무 모델을 새로 학습해 보기도 했다.
물론 기존 snet 데이터셋을 만들어보기도 했다. 나름 성과가 있었다.
HDD를 전면적으로 적용하지는 않았지만, 문제에 대한 해답을 테이블에 작성하고 장단점을 비교해보기도 했다.
이전에 모아둔 3백만개의 데이터에 대한 메타데이터를 어떻게 만들지 생각할 때 그렇게 했다.
그런데 아무리 생각을 해봐도, DB를 안 쓰는 것이 정말 가치가 있는지 계속 의심이 되었다.
3백만개 이미지에 대한 메타데이터를 1) 파일로 표현할지 2) Postgresql DB로 표현할지 3) MongoDB로 표현할지 비교했다.
결론은 Postgresql이었고, aiosql을 적용하여 작업을 했다.
또한 스키마를 매우 미니멀하게 작성했고, 이미지 파일에 ID를 부여하여 테이블의 PK로 쓰는 동시에 파일 시스템에서도 찾기 쉽게 했다.
이건 정말로 괜찮았다! DB를 메타데이터로 가볍게 쓰는 방법은 꽤 좋았다.
이렇게 DB로 성공하고 나니 그 전까지 했던 작업들이 오징어로 보이기 시작했다.
다시 보니 이전 작업들은 데이터 출처에 굉장히 의존하는 코드였다.
당연히 재사용성은 없었고, 이번에도 다른 이름의 모듈에 비슷비슷한 코드가 반복되고 있었다.
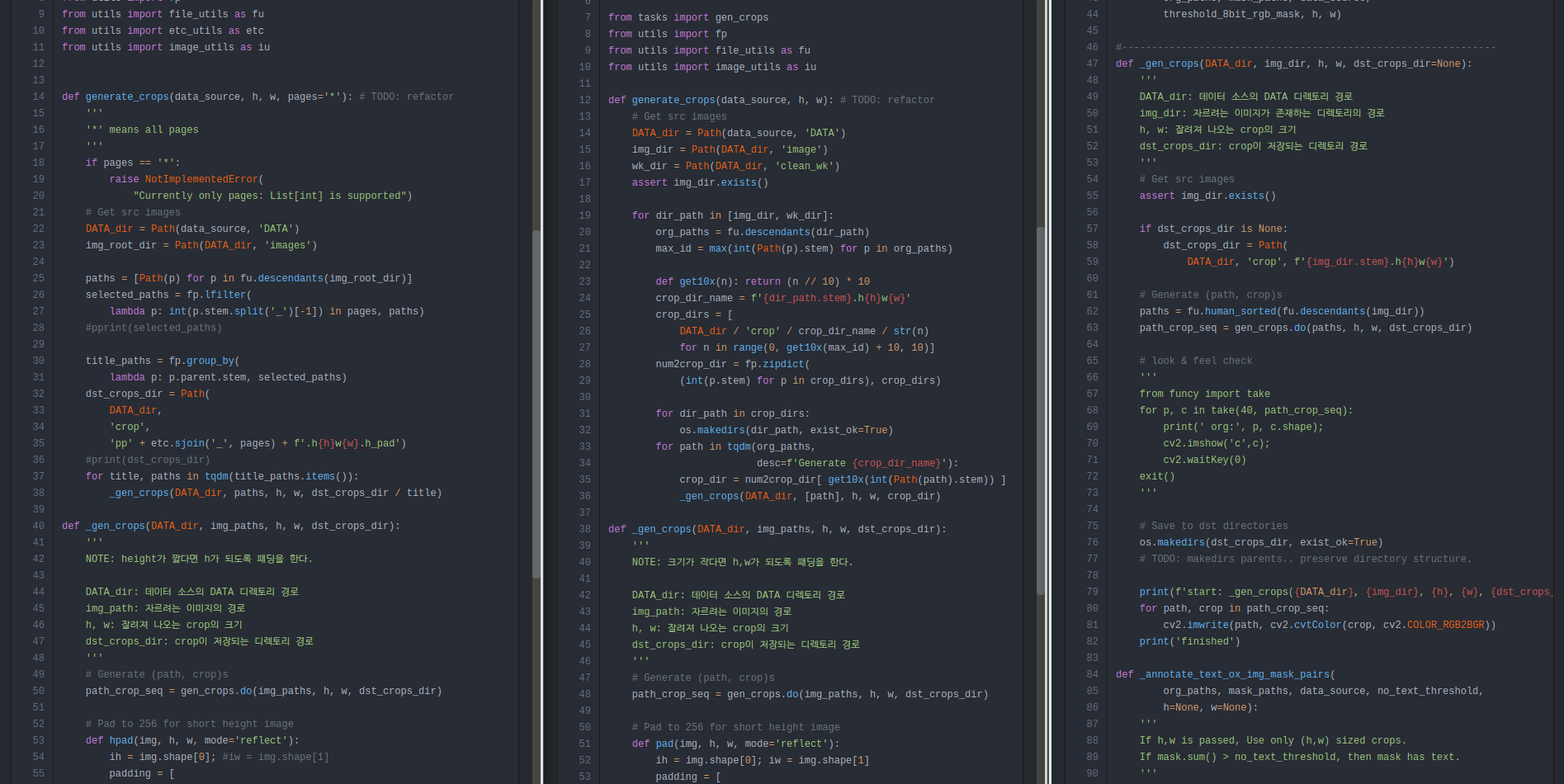
3백만개 이미지 작업 전에는 manga109나 기여받은 데이터들을 파일을 이용하여 처리했는데
뭔가 새로운 처리 기능을 넣으려면 매번 작업을 새로 해야 했다.
아무튼... 이번에도 결국 재사용은 없었고... 제대로된 모듈화도 또 실패했다.
새로운 기능을 어디에 넣을지 여전히 모르겠고, 한번 넣은 커맨드는 다시 쓰여지는 일이 거의 없었다.
그리고 테스트를 붙일 구석이 전혀 없었다.
더 나은 방법이 없을까?
답은 작은 기능을 조합하여 새로운 기능을 만드는 것이다.
잘 테스트되어 검증되어있는 작은 조각들을 조합하여 새로운 기능을 만들 수 있다면, 훨씬 나을 거라 생각했다.
그리고 재사용성에 대해서, 이런 생각도 했다: 애초에 데이터를 하나로 통일해서 표현했으면 됬던거 아냐?
그러나 이 프로그램은 그러기에는 너무 늦었다.
그래서 나는 6번째 시스템 개발을 결심한다.
시행착오가 아니라 실패다
6번째 프로그램을 새로 짜자고 생각했던 때는... 이제 학위 논문을 쓸 시간이 한 달밖에 남지 않은 시점이었다.
그냥 사실상 망한 거나 다름 없다. 더는 불가능하다....
나는 완전히 실패했다. 제 시간에 필요한 프로그램을 만들지 못했다.
그대로 가려면 5번째 프로그램을 쓰면서, 억지로 실험 결과를 내고 논문을 써야 했다.
나는..... 나는 납득하지 못했다. 시간이 더 필요했다. 이렇게 끝낼 수는 없어.
그런데 어느날 지도교수님께서 말씀하셨다.
"학위 논문보다 그것을 뒷받침하는 시스템이 더 중요하다"
나는 교수님이 논문을 쓰는 걸 원하는 줄 알았는데, 아니었다.
사실 이런 시스템을 만드는 걸 교수님께 딱히 알리지는 않았다.
이건 내가 개인적으로 하는 일이기에 교수님도 딱히 건드리지 않았다.
(교수님은 내가 몇번이고 실패한 걸 잘 모르신다)
나는 논문을 써야하는 줄 알았기에 늘 조금 죄스러운 마음이었다.
근데 시스템을 만들라고? 그게 더 중요하다고?
ㅗㅜㅑ
그건 내가 2년 내내 했던 거다
딱 기다려라...
결론
그래서 내가 결국 뭘 했냐면, 즐거운 마음으로 학위 논문 심사를 연기했다.
심사는 8개월 뒤다. ㅋㅋㅋㅋㅋ; (주의: OLD - 완전히 미쳐버린..)

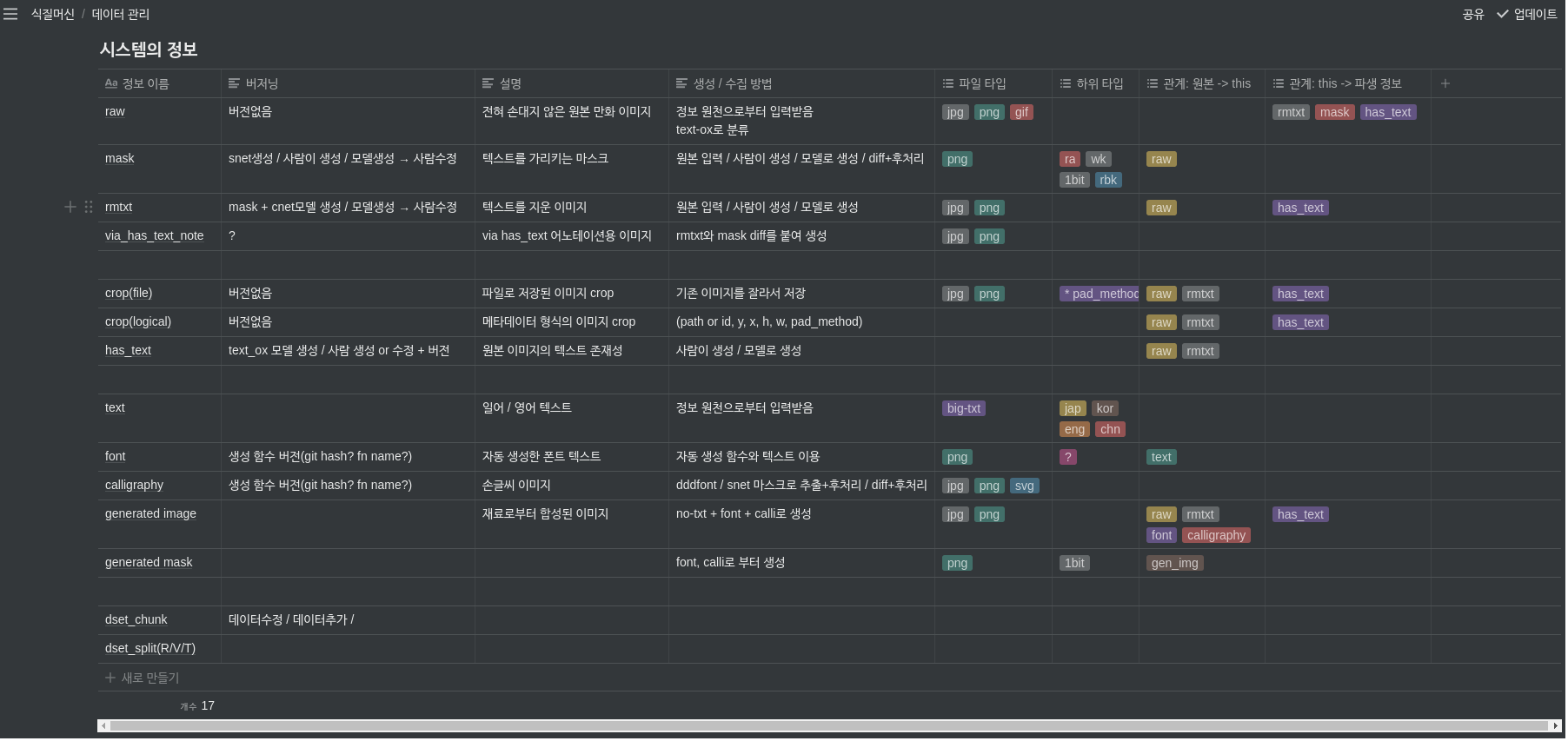
지금은 6번째 프로그램을 개발하고 있다.
이전처럼 바로 프로그래밍에 뛰어들지 않고, 계속해서 생각하고 있다.
노션을 이용하여 해결해야 하는 문제와 요구사항을 정리하고, 시스템이 처리하는 정보에 대해 표로 정리하고 있다.
그 외에도 시스템이 필요로하는 모듈로 적용 가능한 라이브러리와, 각종 외부 툴을 조사하고 실험해보고 있다.
문제를 생각하고, 해답을 하나 이상 생각한다. 여러 해답을 테이블로 비교한다. 비판적, 비관적으로 생각한다.
설계는 무언가 쪼개는 것이란 걸 명심하고, 열심히 쪼개고 있다.
확신이 들 때까지 생각과 설계만 할 것이다.
설계에 확신이 서면, 그때부터는 마일스톤과 데드라인을 정하고 애자일하게 프로그래밍할 생각이다.
하나의 모듈(데이터 관리)에 집중하는 것이 아니라, 모델 학습과 결과 평가까지 전체 시스템을 조금씩 만들어간다.
그리고 뭔가 잘못되었다면 내 생각, 설계를 수정한다. 반복한다......
그런 식으로 개발하려 한다. 이게 내가 수많은 실패에서 배운 해답이다.
이제 정말 마지막이다. 5번이면 충분하다. 더 이상 실패는 없다.
23년 추가
